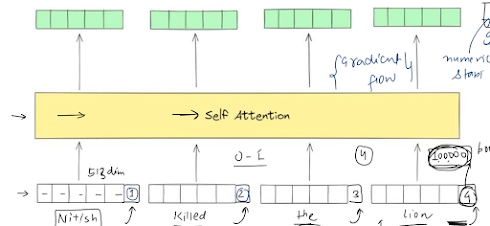
Masked Self-Attention : Statement: What is autoregressive model? Model that predicts next value based on previous data. Like, next word prediction, to predict the next word, you need to have a previous word. Now, the qs is why it behaves differently during training and inference? To get this answer, and prove the above statement, 'masked self attention' comes into the picture. --------------------------------------------------------------------------------------------------------------- Now, focus on below example. During Inference: To predict the next word, we will use the previous word as input. During Training : - If you look at this diagram, observe that, even if the model is predicting the wrong word, we are passing the correct word from our dataset as the input in next step, so that the model learns correctly. So, during training, we are not dependent on previous data. Hence, it is non-autoregressive during training. Now, pose a little, and think for a while, what does s...