Random Forest
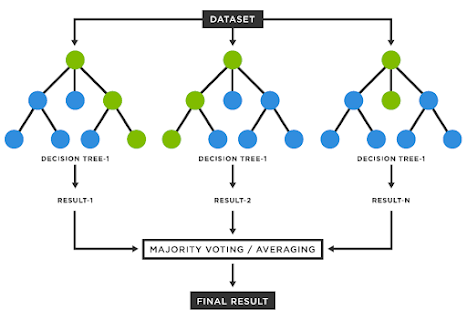
The core idea behind Random Forest is to create a "forest" of decision trees, each built on different subsets of the data and using a random subset of features. It's used for both classification (like spam detection) and regression (like predicting house prices). A type of bagging that uses decision trees to improve prediction accuracy and robustness. How Does It Work? Data Sampling : Randomly pick samples from your data. Tree Building : Build decision trees on these samples. Voting/Averaging : For classification, trees vote for the most common class. For regression, the average of predictions is taken. Example: Predicting House Prices Imagine we want to predict house prices based on features like size, location, and age of the house. Step-by-Step Collect Data : Gather data on house prices along with features like size, location, and age. Create Subsets : Randomly create multiple subsets of this data. Build Trees : For each subset, build a decision tree. Each tree might ...

