DBSCAN Clustering
.png)
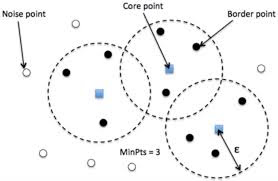
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) Why we need DBSCAN? While K-Means clustering is a popular choice, it struggles with noisey data as it considers outliers as a cluster. Enters DBSCAN, an algorithm that not only detects the outliers but also removes them. So now, let's understand, How this algorithm works? Key Ingredients of DBSCAN Epsilon (ε) : Think of this as the maximum distance between two points for them to be neighbors. MinPts : The minimum number of points required to form a dense cluster. Core Point : A point with at least MinPts neighbors within its ε-radius. Border Point : Close to a core point but with fewer than MinPts neighbors. Noise Point : Points that don’t fit into any cluster – the outliers. Why Choose DBSCAN? Outlier Detection : Naturally identifies noise points, making it great for spotting anomalies. No Predefined Clusters : Unlike K-Means, you don’t need to specify the number of clusters beforehand. Flexibility : Handles cl...
