Ridge & Lasso Regression
Before going for ridge & lasso regression, you need to understand few terminologies first.
So, Let's start!
Imagine you're teaching a robot to recognize different types of fruits based on their weight. You decide to use a simple model: if the fruit weighs less than 100 grams, it's a grape; if it weighs more, it's an apple.
Bias:
Imagine all the fruits in your training data are apples, and there are no grapes. Your model will learn that everything is an apple, leading to a high bias. This is like teaching the robot that everything, regardless of weight, is an apple.
Variance:
Now, imagine your training data has a mix of apples and grapes, but you teach the robot to recognize each fruit by its exact weight, including the weight of imperfections and stickers. Your model will learn these specific details, leading to a high variance. This is like teaching the robot to identify each fruit by its unique weight, even if it's just a tiny bit different.
In this example, a balanced model would consider a reasonable weight range for each fruit, ignoring small variations that don't affect the overall classification.
Overfitting :
- Model performs well on -> Training data (Low Bias)
- Fails to perform well on -> Testing data (High Variance)
- Model's accuracy is bad for both Training and Testing data. (High Bias & High Variance)
|
Model 1 |
Model 2 |
Model 3 |
|
Training Accuracy : 90% |
Training Accuracy : 92% |
Training Accuracy : 70% |
|
Testing Accuracy : 80% |
Testing Accuracy : 91% |
Testing Accuracy : 65% |
|
Overfitting |
Generalized Model |
Underfitting |
|
Low Bias |
Low Bias |
High Bias |
|
High Variance |
Low Variance |
High Variance |

- Ridge Regression (L2 Regularization) :
- Prevents Overfitting, How?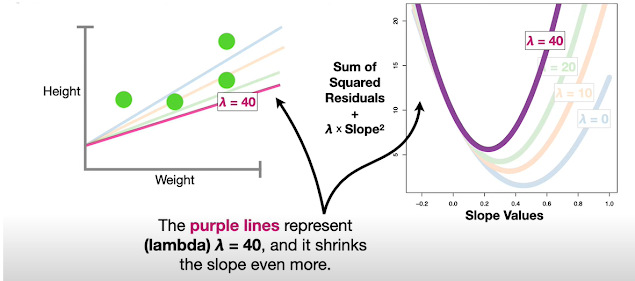
- Lasso Regression (L1 Regularization) :
- Prevents Overfitting




Comments
Post a Comment