Positional Encoding in Transformer
1. Why Position Matters in Transformers?
- Transformers rely on self‑attention, which processes tokens in parallel.
- This means, unlike RNNs, they don’t inherently know the order of words.
- So, sentences like “Ravi killed the lion” vs. “The lion killed Ravi” would look identical to a vanilla Transformer—clearly problematic!
🧪 Idea #1: The Naïve Approach
A simple fix would be to add index/position of the token in an embedding vector.
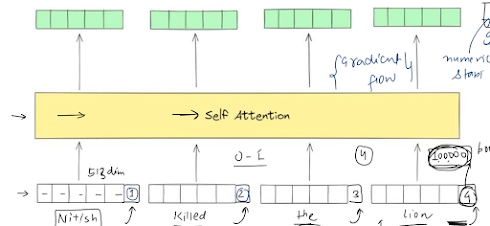
Issues:
Unbounded values: Position IDs can become huge (e.g. 100,000+ in long texts), destabilizing training.
Discrete steps: Sharp jumps between integers disrupt gradient flow.
🧪 Idea #2: Normalize the Position Numbers
What if we divide the position numbers by a constant to make them small and smooth?
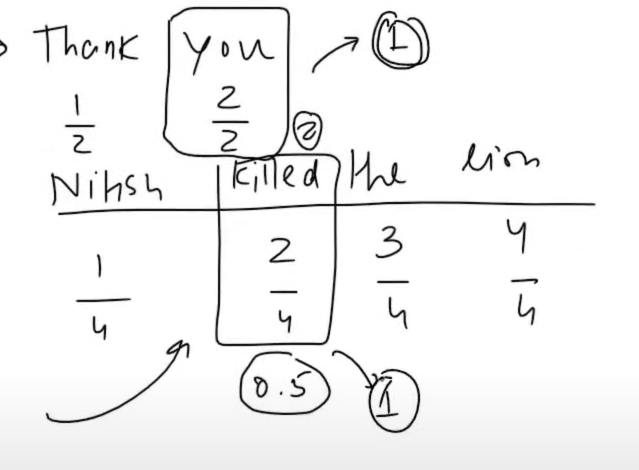
That helps a bit—values don’t explode anymore.
Issues:
Now, if you observe, in both the sentences, the word at second position has got the different values.
1 for sentence1, and 0.5 for sentence2.
so, the Neural network will get confused while training, what actually is the second position.
The neural network prefers continuous values, not discrete values.
Can't capture relative positioning. we won't know that word_X is 3 steps ahead of word_Y.
Discrete Position:

Relative Position:
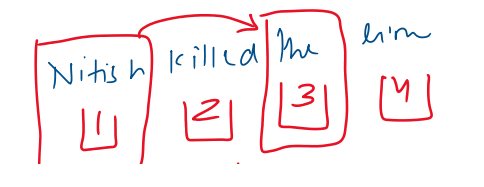
The model should know:
How far apart two words are
Whether a word comes before or after another - 'the' comes after the word 'Nitish'
So, we need a function which is :
Bounded (values between –1 and 1)
Continuous
Periodic (captures repeating patterns, and hence relative distances).
🧪 Idea #3: Use the sine function
It is bounded, continuous and periodic.
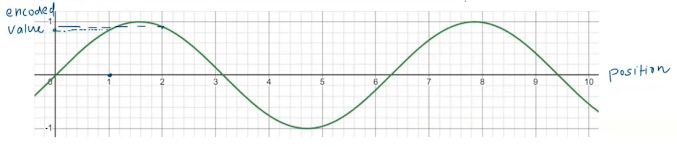
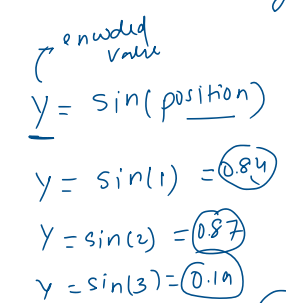
Issues :
If we only use sin(position), some positions might get the same values again and again due to the repeating nature of the wave. That causes clashes—different positions looking the same!
🧪 Idea #4: Use Both Sin and Cos with Different Angles
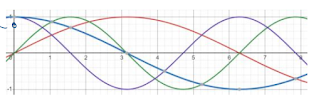
We combine sin and cos functions
We use different angles (frequencies) for each dimension in the vector
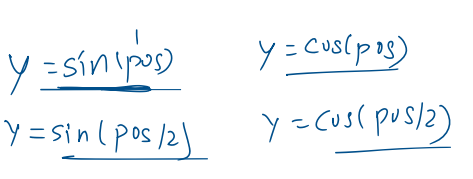
Issues:
But what if, the text is too large and this too, starts repeating.
🧪 Idea #5: How do we decide this sine cosine frequency?
Solution given in paper : Attention is all you need.
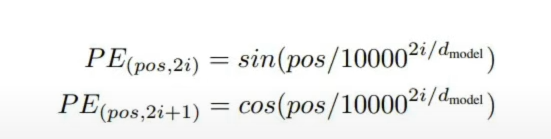
Where:
i = current dimension number
d = total dimensions
Let's say total dimensions=6, now we have 2 formulas, so will go till halfway only, ( 0,1,2).
And because of the presence of 2 formulas(sin and cos), we will get the values of 6 dim by traversing only till 3.
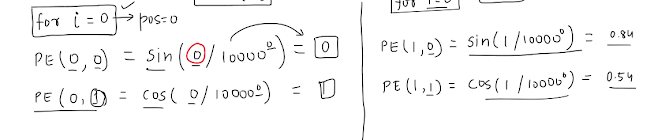
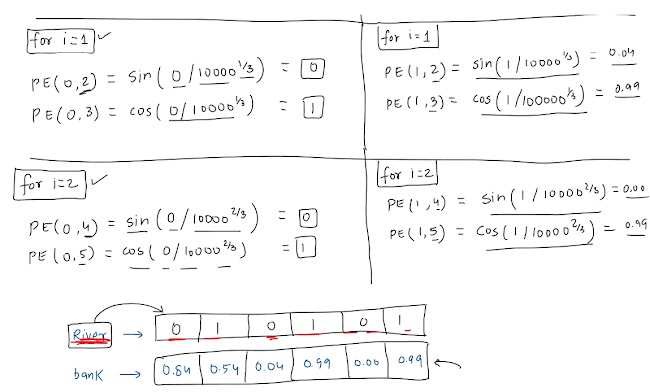
Final Step :
We will add this positional vector with its word embedding vector.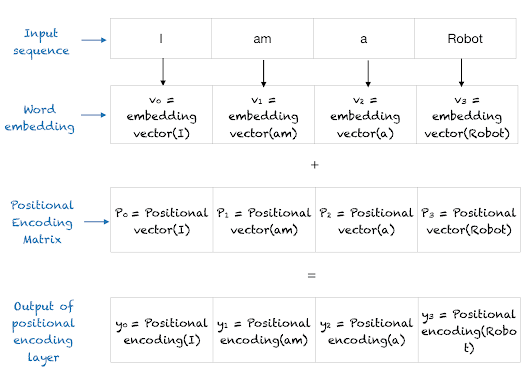
Why Do We Add the Position Vector Instead of Appending It?
If we append the positional vector, the input size will double (say, 512 for word + 512 for position = 1024). That would increase model complexity.Instead, we simply add the positional vector to the word embedding. This keeps the size same (512), and the model gets both meaning + position together in one vector. It’s simple and effective.
Reference:
https://youtu.be/GeoQBNNqIbM?si=ZTpSLl-jJdAiNJeh



Comments
Post a Comment