Train-test split & Cross-Validation
Train-test split :
Let's say we have a dataset with 100 samples.
Now, if we train the model on all 100 samples and test the results from this 100 samples only, then even if the data is overfitted, we won't know!
So, to avoid this, we use train-test split

In train-test split, we divide the data into 2 parts:
1) Training Set :
We use 70-80% data as a training set. So, for above example we won't train all 100 samples but we will train the model on 80 samples.
2) Test set :
The test set usually contains the remaining 20-30% of the data. So, for above example we will test model for the rest 20 samples.
The test set is used to evaluate how well the model generalizes to new, unseen data. The performance metrics (such as accuracy, precision, recall, etc.) are calculated based on the model's predictions on the test set.
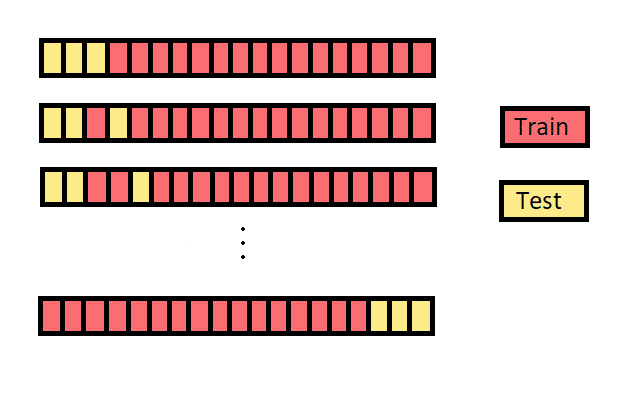
Cross-validation :
Divides the dataset into multiple folds. Some of the folds as training set & some of the folds as testing set. This process is repeated multiple times, each fold is used as the test set exactly once.
Here's a simple example to illustrate cross-validation:
Let's say we have a dataset with 100 samples. We decide to use 5-fold cross-validation, meaning we will split the data into 5 subsets, each containing 20 samples.
Split the Data: We divide the dataset into 5 folds:
- Fold 1: Samples 1-20
- Fold 2: Samples 21-40
- Fold 3: Samples 41-60
- Fold 4: Samples 61-80
- Fold 5: Samples 81-100
Iterative Training: We then iterate through the following process 5 times, each time using a different fold as the validation set:
- For iteration 1: Train on Folds 2,3,4,5, Validate on Fold 1
- For iteration 2: Train on Folds 1,3,4,5, Validate on Fold 2
- For iteration 3: Train on Folds 1,2,4,5, Validate on Fold 3
- For iteration 4: Train on Folds 1,2,3,5, Validate on Fold 4
- For iteration 5: Train on Folds 1,2,3,4, Validate on Fold 5
Model Evaluation: After the iterations are complete, we have used each fold as the validation set exactly once. We can then average the performance metrics (such as accuracy, precision, recall, etc.) from each iteration to get an overall estimate of the model's performance.
Cross-validation helps to provide a more accurate estimate of the model's performance compared to using a single train-test split, as it allows the model to be trained and tested on different subsets of the data. This can help to identify potential issues like overfitting or data bias.
Generally, in the code you will use below variables:
x_train, y_train, x_test, y_test, y_pred
Assume that you want to predict salary based on the experience in years.
So, x = experience
y = salary
x_train : 70% data from experience
x_test : rest 30% data from experience
y_train : 70% data from salary
y_test : rest 30% data from salary
y_pred : we give x_test (experience) as input and it will predict salary(y_pred)
So, here y_test = actual salary
y_pred = salary predicted by model
Types of Cross-Validation :
(Using Example of 100 samples)
1. K-Fold Cross-Validation: For our example dataset of 100 samples, if we choose K=5 for 5-fold cross-validation, each fold would consist of 20 samples. we train on 4-folds and test on 1-fold

2. Stratified K-Fold Cross-Validation: If our dataset has two classes - Male(M) & Female(F), each with 80 and 20 samples making total of 100, each fold in 5-fold stratified cross-validation would contain 16 samples for M and 4 samples foe F.

3. Leave-One-Out Cross-Validation (LOOCV): In LOOCV, the model would be trained on 99 samples and tested on 1 sample, repeated for all 100 samples.

Image Source: ISLR 4. Leave-P-Out Cross-Validation: For leave-3-out cross-validation, the model would be trained on 98 samples and tested on 3 samples, repeated for all possible combinations of leaving out 3 samples.
5. Repeated K-Fold Cross-Validation: You might perform 5-fold cross-validation 10 times, each time with a different random split of the data.
First iteration:
Fold 1: Random samples 1-20 Fold 2: Random samples 21-40 Fold 3: Random samples 41-60 Fold 4: Random samples 61-80 Fold 5: Random samples 81-100
Second iteration:
Fold 1: Random samples 11-30 Fold 2: Random samples 31-50 Fold 3: Random samples 51-70 Fold 4: Random samples 71-90 Fold 5: Random samples 91-100, 1-10 (wrap around)
and so on...


Comments
Post a Comment