ML Notes personal

L21:
Types of Analysis :
| Type | Variables | Purpose | Complexity |
|---|---|---|---|
| Univariate | 1 | Describe single variable | Low |
| Bivariate | 2 | Find relationships between pairs | Medium |
| Multivariate | 3+ | Understand complex interactions | High |
Univariate :
only one variable, lets say we need to see the age of people travelling in business class.

Bivariate :

Multivariate :

We are observing 3 variables at a time:
1. the higher the bill amount, the higher the tip
2. which gender gave the tip? male or female


L22 :
Pandas Profiling




L23:
Feature Engineering

1. Feature Transformation




Feature scaling means setting the values in some range. ex (-1 to 1)

the sum of 2 cols and then, again, categorize it with family size in [small, medium, large]
3. Feature Selection :
keep the necessary columns only and remove unnecessary ones.
-- Doubt in feature construction vs feature extraction, will be solved later on.
Feature Scaling
why?

here, salary feature will dominate the model, hence, no accuracy due to insufficient weight on imp columns such as age.
Types:

Normalization (Min-Max Scaling)
Scales data to a fixed range, typically [0, 1]
Formula: (x - min) / (max - min)
Characteristics:
- Preserves the original distribution shape
- Bounded to a specific range (usually 0-1)
- Sensitive to outliers (they can compress the rest of the data)
- Also called Min-Max scaling
Example:
from sklearn.preprocessing import MinMaxScaler
# Original data: [10, 20, 30, 40, 50]
# Normalized: [0, 0.25, 0.5, 0.75, 1.0]
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)Standardization (Z-score Scaling)
Centers data around mean=0 with standard deviation=1
Formula: (x - mean) / standard_deviation
Characteristics:
- Creates data with mean=0, std=1
- Not bounded to a specific range
- Less sensitive to outliers
- Preserves the relationship between data points
- Also called Z-score normalization
Example:
from sklearn.preprocessing import StandardScaler
# Original data: [10, 20, 30, 40, 50] (mean=30, std≈15.81)
# Standardized: [-1.26, -0.63, 0, 0.63, 1.26]
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)Geomatic intuition
Entire data has center 0,0
original data position vs after performing standardization. Before standardization :
After Standardization : 
so, now, both the cols will get equal priority.model performs better after scaling.what happens for outliers?The results are same only.Let's say 100 is a outlier.NORMALIZATION: [Gets affected by outlier)Without outlier: [1,2,3,4,5]|----|----|----|----|0 0.25 0.5 0.75 1.0 ← Good spreadWith outlier: [1,2,3,4,100]||||--------------------|0 0.03 1.0 ← All normal values crushed together! (its not good, very difficult todistinguish between 1 to 4)STANDARDIZATION: [ Doesn't get affected by outlier)Without outlier: [1,2,3,4,5]|----|----|----|----|-1.26 -0.63 0 0.63 1.26 ← Good spreadWith outlier: [1,2,3,4,100]|---|---|---|---|--------------------|-0.53 -0.51 -0.48 -0.46 1.97 ← Still can see differences
Types of Normalization:
Geomatric intuition for normalization :Just placing the entire data between 0 to 1Encoding Categorical dataordinal,nominal and label encoding

























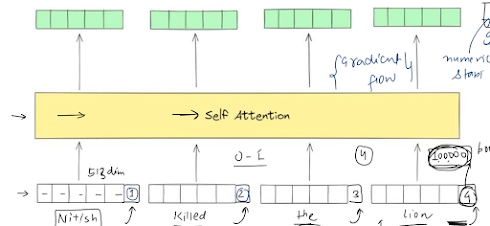

Comments
Post a Comment