Types of Neural Networks
Perceptron :
x1, x2 = input
w1, w2 = weights
b = bias
z = sum of all these
now, z will be given to activation function
For example, step function, output will be 0 or 1
How to use it?
You train the model and find the value of w1, w2 and b
Perceptron is a line :
It's a binary classifier, that divides data into 2 regions
No, matter how many features we have, it will always divide the data into 2 parts
Limitation : Perceptron will be used on linear data onlyCode :
Prediction using perceptron
How do we find the correct values for weights?
Step 1 : we take the random values for each weight
Step 2 : randomly take one data point, if the point is on correct region, do nothing, else, move the line
Step 3 : repeat step 2 for 1000(n) times
How do we know that point is on correct region?
- we know that blue points should be in -ve region and green points should be in +ve regions
- so, we just have to make line transformations accordingly
How do we move towards correct values of A,B,C?
1. If you make change in C, line moves parallely
2. If you change x, line will move on the x axis, y is still same
3. same for change in y
Example :
If you want to move point in -ve region, you subtract it from line
If you want to move point in +ve region, you add it in line
but , in this way line will move very drastically, so we use learning rate.
Algorithm :
Instead of using these 2 if conditions, it can be simplified to this 1 formula
Explanation :
3rd row = green point
4th row = red point
This method will find a line, but it is not gauranteed that it is the best fit line, because, in the empty space between 2 regions, there can be multiple lines.
Perceptron loss function
So, how do we find the values such that this Loss becomes minimum
Intuition :
Assume that w2 and b are constant, so for w1, we have to get a point where L is minimum.
For that , we will use gradient descent.
Problem with Perceptron :
- Works only on linear data
xor dataset, perceptron fails here
MLP - Multi layer perceptron :
k=lay
er no where this is going to
i = from node
j= to node
bij => i=layer no, j=node no.
Perceptron with Sigmoid
Intuition :
how do we overlap?

so, for this diagram, MLP will look like below :
In multi class classification, there will be multiple nodes in output layer. dog, cat, cow
Hiden layers with correct Activation function can identify any data pattern
Trainable parameters in Neural network
what is it ? - Sum of weights + biases at each layer
Formula : Sigma (no_of_nodes_in_current_layer*no_of_nodes_in_next_layer) + bias aka no_of_nodes_in_next_layer
26 trainable params in above image
Once the training is done, make prediction
cost function vs loss function
loss func : applies on single row for each row
cost func : applies on batch data
mae (Mean Absolute Error)
bce (Binary Cross-Entropy)
CCE (Categorical Cross-Entropy)
SCE (Sparse Categorical Cross-Entropy)
| Task Type |
Loss Function |
Output Activation Function |
| Regression |
MSE / MAE |
Linear (None) |
| Binary Class. |
BCE |
Sigmoid |
| Multi-class |
CCE / SCE |
Softmax |
Backpropagation
First 3 done
Notice that, inside each iteration, step c will be performed 9 times as we have 9 weights
Finally, it will look like this :

Memoization :
it is the concept where we use more memory to save time complexity
Types of Gradient Descent
Batch/Stochastic/Mini batch
lets say epoch=10
Batch : 1 to 50 rows for each epoch
=> 10 times weight update
Stochastic : same but shuffle the data before starting prediction => 500 times weight update
stochastic is faster than batch because it will converge and give better results in lesser epochs
spikey nature of SGD has one drawback : gives approx minimum value around the actual value, not the exact
Mini batch :
The weight didn't change much 1 to 0.999, this ain't helping to minimize the loss
1) less no. of hidden layers
One more problem with Gradient
Problems in Neural Networks and its Solutions
Overfitting in NN- Solutions :
Dropouts :
for each epoch, you randomly switch off some nodes in input layer and hidden layer.
p=0.5 means, we can switch off 50% nodes at each layer
During prediction, we use all the nodes.
During testing, we multiply the weight by 0.75 as the node was present only 75% of time and 25% of time, it was misssing.
p value :
Add penalty in cost function
This formula helps reducing weight, hence reducing overfitting. L2 is better than L1, because in L1 there are chances that weight become 0, in L2, it will be nearly equal to 0, but not the exact 0.
Orange curve= Regularized weights
Blue = Normal weights
Why do we need activation functions?
- to introduce non-linearity in data
Activation Functions :
1. Sigmoid - used for binary classification
- non-linear
- differentiable
Disadvantage : vanishing gradient problem, so only used in output layer
- computationally expensive because of exponential in formula
- non-zero centroid, it means you can either only add in weghts or either subtract, both are not possible, so slow training
2. tanh
range(-1,1)
RELU
Non-Zero Centroid : This problem is solved by Batch Normalization
if more than 50% neurons die, then, its a dieing Relu problem
why dead?
- so problem occurs when z is -ve.
Weight Initialization :
What not to do?
1. never keep all weights as 0 - derivative will be 0 and hence no change in weights
2. Never keep same value for all weights - in this case most of the term will have the same value and z11=z12 plus a11=a12 and that's why, in the next layer, no matter how many neurons you take, it will always work as a single neuron, hence, no linearity, and wrong model
3. randomly initialize weights with small values- vanishing gradient and slow convergence
4. randomly initialize weights with large values - vanishing gradient and slow convergence, spikes and unstable training because very much different value for gradient
What to do?
1. xavier initialization - normal
All these formulas have been derived by scientist by experiments.
Batch Normalization
g(z) is an activation function
Why we are using gamma, beta? it is the opposite of normalization, right? because it gives NN the flexibility, not every data needs normalization, so it can keep or remove it.
gamma and beta will change during training, back propagation
Advantages of Batch Normalization :
1. same LR throughout the training
2. local minima
Solution :
EWMA
Remember one thing, newer point has higher weightage than the older point
Optimization Technique
Keras Tuner -
works as Gridsearchcv for neural networks
CNN
CNN will work better than ANN for images
Why ANN is not good?
Too many weights and chances for overfitting
How will we know if it is an edge or not
drastic change in colur of 2 adjacent pixels
example taken of horizontal edge detection filter
- original image size is reduced, so middle part will have more impact than the edges
- so we should apply padding
If you apply filter on below image, row with index 2 will repeated for each filter window, so it will have high impact than others.
without padding : size is decreasing
with padding : size remains same
stride = step/jump
stride=1
stride=2
the more thr stride, the less the output
size will decrease
pooling makes them location independent
what is convolution?
It is just a filter that applies to the image
CNN Architecture
lenet 5 Architecture
weights, bias and training for CNN, all of these applied to filter
Difference between ANN and CNN
ANN : no. of trainable params depends on input size
CNN : no. of trainable params depends on filter size, so no matter how much data is there, no of weights remains same
Freeze the conco layers and train on FC
this is how you can freeze from specific layer
so, we need non-linearity for multiple usecases.
Example :
Example : multiple outputs - age and some classification
Example : multiple inputs
for a single dataset also, the input size is not same, zero padding will also not work, if curent sentence has 5 words and the largest one has 100, then we are using 95 unnecessary vectors
For the consistency, we provide O0 for 1st one as zero or random
Types of RNN
why?
Forget Gate : Remembers only necessary things
ft=[1,1,1] - after multiplication, model remembers everything
ft=[0.5,0.5,0.5] - model remembers 50% of the things
Input Gate
Gated Recurrent Unit
update :
reset :
for vikaram junior, we will modify vikram's, as there is no mention of conflict for vk jr
Bi directional RNN/LSTM/GRU
why? we need not only previous words but next words also.
2 parts : 1:forward rnn
1 backward RNN
why?
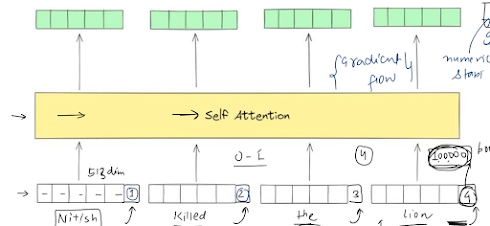
Attention mechanism,
to predict next word in translation, we use previously translated words + all input words according to weights, weights will be calculated by ANN
Luong Attention
___ Play List Completed _____________




























































































































































































































Comments
Post a Comment