🧠 Ridge Regression aka L2 Regularization(Because of Square)
📌 What is Ridge Regression?
Ridge Regression is a regularized version of linear regression that helps reduce overfitting by penalizing large coefficients.
🧮 Key Formula:
Loss=RSS+λj=1∑nβj2
Where:
-
RSS = Residual Sum of Squares (normal linear regression loss)
-
λ (lambda) = regularization strength (also called tuning parameter)
-
βᵢ = model coefficients
-
The penalty term is L2 norm
🎯 Why Use Ridge?
⚙️ How It Works
-
Adds a penalty to the squared values of coefficients
-
Forces coefficients to be smaller, but not zero
-
Helps in bias-variance tradeoff (increases bias, reduces variance)
🔁 Difference from Other Methods
| Method | Penalty | Shrinks Coefficients to Zero? |
|---|
| Linear Regression | None | No |
| Ridge | L2 (squares) | No |
| Lasso | L1 (absolute) | Yes |
🧪 When to Use Ridge?
-
Many features with small effects
-
Multicollinearity present
-
Want to keep all features, but reduce their impact
🧩 How to Choose λ?
📈 Implementation (sklearn)
✅ Pros
-
Reduces overfitting
-
Keeps all features
-
Improves generalization
❌ Cons
Keypoints :
1. when you increase lambda, values converge towards 0, but not an exact 0, high values columns are affected more.
Too high lambda, then, it will underfit.
2. Ideal value of lambda/alpha.
3. Notice how coeffecients are converging towards 0.
when to use ridge regression?
- when no. of input cols are >=2
Now, why it never becomes exactly 0?
It will be possible only if the numerator is 0, but it is very hard to reach 0, because we are having a sum of actual - predicted.
Lambda is in denominator.
Lasso Regression (L1 Regularization)
In ridge regression, coefficient never gets 0, here it can get 0.
Term : sparsity means few coeff are 0.
So, whats the benefit of making them 0?
- when you have very high dim data, (x1,x3000) so, in this case, if we keep all the features, model is most likely to overfit, in lasso, if we increase alpha, then, few cols coeff will become 0, so it is helpful for feature selection.
in the above image, notice the selected row, few features are 0, we can easily ignore them for training.
why it gets 0?
ElasticNet Regression :
Used when you dont know whether to use ridge ot lasso
we take values of lambda and l1_ratio, based on that we calculate a and b
Default value of lambda = 1 and l1_ratio = 0.5
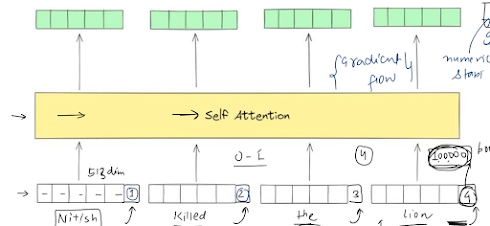
Logistic Regression
Used for linearly seperable data
Logistic Regression (yes, name is misleading — it’s for classification)
actual eq is ax+by+c=0,
but to make it in sigma format, we have added col x0.
1. we go till x no of epochs,
2. select random weights for a,b,c
3. select one random point during each epoch, and ask it if it is at the right side, ad from that points perspective, is the line correct?
4. If yes, do nothing, if no, update weights so that line covers that point in right region.
These are too much operations, so we can use simplified algo.
only 4 possibilities, look at the bottom left corner
now, if you look at top right corner, in the new formula, you will get the same results.
Problem with this technique :
Red line will be predicted by model, but in real, we need to predict black line.
So, now we will make a new approach :
mis-classified points will pull the line towards them
correctly-classified points will push the line, so there will be a time where blue and green both are pushing, so line will be in equilibrium.
so, to solve this, sigmoid function comes into the picture.
so, we are just replacing step function with sigmoid.
instead of 0 and 1, we will get the values between
0.00000000001 to 0.5
and 0.5 to 0.9999999999
when you add something, line will go down. when you subtract something, line will go up.
so, now we have got this output :
so, in this logistic regression, we are taking random points for n no of epochs, so, there will be correct line so many times, but how do we know, that particular line is the best line, for that, we will use loss function called maximum likelihood.
model = actual point colour's probability for all data points
it means, if green point, we will use P(G), for red, will use P(R)
further mathematics,
log loss error equation :
Derivative (d/dx) of sigmoid :
just use gradient descent in logistic regression, and you will get the exact black line.
Accuracy :
How much accuracy is good?
- totally depends on usecase.
- for medical and self driving car, 99% accuracy is bad, because 1 person will die or car accident
- for swiggy sales increase during holidays, 80% accuracy is also good
Confusion Matrix :
FP
TYPE 2 Error :
FN
When accuracy score is misleading?
- example , defect detection, 99% black part, only 1% white part, so even if model predict entire black masks, the accuracy will be 99%
Precision, use when FP is more important, TYPE 1 error
Recall, when FN is more important, TYPE 2 Error
F1 Score :
The
F1 Score is the
harmonic mean of
precision and
recall.
The harmonic mean ensures that the F1 score is low if either precision or recall is low
For example:
-
If precision = 1.0 and recall = 0.0, the F1 score is 0.0, not 0.5. That’s important — it reflects the fact that zero recall means your model missed all real positives, which is bad.
same for recall and f1 score.
Softmax Function :
sum of these 3 probabilities will be 1.
Polynomial Features in Logistic Regression :
Logistic regression is mostly used in linear data only, for non-linear, we have better algorithms, but it is just for the concept understanding that polunomial logistic regression do exist.
Decision Tree :
Geomatric Intuition :
1. Now, we always have to decide the best node to start from, and then, best node at each level and step, we will see how to do it in future.
2. how to decide splitting threshold for numerical data?
Also, known as CART - Classification and Regression Tree
Information Gain
entropy range : 0 to 1 always
Gini Impurity :
Range : 0 to 0.5 always
🔍 Interpretation:
-
0 → Pure (only one class)
-
> 0 → Impure (more than one class)
-
Maximum Gini (for two classes) is 0.5, when classes are perfectly balanced (50/50)
For numerical data :
so, for each value, we will have 2 datasets.
Overfitting in Decision Trees :
the green point should have been considered part of red to avoid overfitting
Underfitting in Decision Tree:
since, 80 are yes, will predict yes always
So, we have some hyperparameters for the depth of the tree.
min_samples_split = 4
-
min_samples_leaf = 3
Step 1: min_samples_split : Can we split this node?
Step 2:min_samples_leaf : After I split, will each leaf (ending point) have enough support? Is the split valid?
Say the split would result in:
-
Left child: 2 samples ❌
-
Right child: 8 samples ✅
But you set min_samples_leaf = 3, so the left child is invalid because it’s too small. This split will be rejected.
more params :
max_no_of_leaf_nodes
minimum_decrease_in_GiniImpurity
etc..
purity means : all values are same after that node
impurity meanse, col contains more than one unique values.
1. Voting
after the prediction from 1 layer, another model is placed, which will predict the final output.
checkout bagging, boosting blog first. then continue:
diff color lines are predictions of diff models.
1. helps achieving low bias+low variance
When to use?
Always.
Voting Ensemble
Assumptions :
1. each model is different from each other
2. each model has at least 51% accuracy
Classification :
hard voting vs soft voting :
soft voting gives you score as well.
Hard voting gives you best one directly.
1. bootstrapping - split dataset
2. aggregating - combine output of all models
note that, in bagging, all the models are of same algo, such as all knn, or all svms, but it is not mendatory, you can have different algo, but think practically, it won't make any sense, so we keep same algo.
now, when we want to test on some data point, it will always pass thriugh all the models, and whatever is the majority, we will take that as a final prediction.
4 Types :
Bagging : Row sampling with replacement(can have duplicates)
Pasting : Row sampling without replacement(no duplicates)
Random Subspaces : Column sampling with or without replacement
axis=0 or 1 will decide row or column
Random Patches : Row & Column sampling with or without replacement
Bagging, or bootstrap aggregating, is a useful ensemble learning technique when you have a model with high variance and are concerned about overfitting, or when you want to improve the stability and accuracy of predictions. It's particularly effective for unstable models like decision trees.
in the reality, you can directly use bagging like this :
features = column
now, during this random selection and replacement, there is a high chance of duplication and missing some rows or columns, for that you cab set oob_score=True
oob = out ot bound
you can test on those rows and columns, so basically you are using them as a testing data
Bagging vs Random Forest :
1)
bagging can have any algorithm for model training.
Random Forest is always trained on Decision Trees.
2)
Bagging : Column sampling happens at tree level
Random Forest : Column Sampling happens at each node of tree
OOB Score will be used to take skipped rows as part of validation data.
RF in Feature Selection :
here, it is a digit dataset, middle part shows the digit, 1 pixel = 1 feature
rf predicted : light color features are important
Adaboost :
let's say, 5 rows, for starting we have assigned equal wight alpha = 1/5=0.2 to each row.
let's say, we are using decision tree for prediction, we got y_pred, now, lets assume that out of 5, 1 row's prediction is wrong.
so, now, we will calculate alpha based on error for each row.
lets say, we have 3 models, a b c -> a has 0% error rate, aways correct, b has 100% error rate, always wrong, c has 50-50.
now, if you think carefully, a and b our equally useful. for b, we can just do 1-prediction, so it will always be true.
so, the graph looks like this, u shaped, but in negative
low error = low alpha = no need to focus more
high error = high alpha = need to pay high attention
take the new weight, and normalize it for sum=1
put normalized values in range,
select 5 random values between 0 to 1 and see it falls majorly in which row?
this is called as upsampling, take these rows only for next training.
so, take 1st, 4th rows, and 3rd row for 3 times, just remove the other 2 rows(2nd and 5th)
below is a different dataset, but observe that row with [0 1 5 ...] is repeating so many times.
this is a combined prediction.
when to use bagging and boosting?
bagging :
1. when you have LBHV model- fully grown decision tree
2. parallel training
3. all model have same weights
boosting :
1. when you have HBLV model - shallow decision tree
2. sequential training
3. all model have different weight(alpha)
KMeans Clustering
b. select 2 random points (k=2) as node
c. for all other points, measure its distance from both the nodes, and put it in the closest cluster
d. calculate centroid for both clusters(look at x mark)
e. repeat step c
f. repeat step d
when to stop? - when current and last centroid position is same.
How to decide value of k?
using elbow method :
Terminology : wcss
from centroid, distace of all points
plot a graph, calculate wcss for k=1, k=2, k=3,....max usually we go upto 20
k=1
k=2
plotting point = sum of wcss1 and wcss2
k=3
.....
Finally, select the elbow point.






































































































Comments
Post a Comment