ML notes personal 4
Gradient Boosting

How it works?
step 1 : model 1 - it always returns the avg value of output col, pred1
step 2 : calculate residual 1 -> predicted-actual = res1
step 3 : make a decision tree iq, cgpa and res1
step 4 : make pred2
step 5 : res2 = actual - (pred1 + LR*pred2)

step 6 : again make dt based on iq, cgpa, res2, and repeat till res is nearly = 0
Gradient Boosting for classification :
step 1 : simple model

step 2 :

this is the log ans, but we need probability, so

step 3: calculate error

step 4 : make model2

and repeat
Final output :

Some intuition :
calculate log _odds for each leaf node using given formula

detailed explanation for 1 node :

observe that number of samples=2, so, in sigma, we are calculating for 2 values, highlighted with red color in table
so, for the column pred2(log_odds) is sum :
prev logodds + current leaf's loggodd

and loop..
res2= actual-current_probability
If some new point comes, this is how we will make prediction :

0.35<0.5, so ->0
Stacking Ensemble


step 2 :
take base models output as an input and real package as expected output , and then train a meta model.

problem :
for the base models, you are predicting on same data on which the model was trained
solution :
1. blending
2. k-fold stacking
1. Blending

level 0 = entire dataset D0
level 1 = 2 subsets D1, D2
level 3 = subpart of D1 = D3, D4
steps:
a. train base models on D3
b.perform prediction of base models on D4
c. train meta model
d. predict on D2
2. k-fold stacking
step 1:

step 2 : take their predictions and train meta model

Multi layer stacking

where k-means fail??

why?
because it measures distance from centroid
solution :

1. Agglomorative Hierarchical Clustering


the matrix will look like this :

merges the nearest ones

2. Divisive Clustering
its the opposite, it splitts from larger

We have diff types of agglomoritive clustering based on how we calculate the distance between 2 clusters.

1. single link : calculate ditance between each points in both clusters, and then take the min dist.
works best if both clusters have good distance between them, fails in case of outliers

2. same but take max distance
it solved outlier case
disadvantage :
can break a big cluster

3. group/avg - balance between min and max
avg of all distances
4. ward - default for sklearn
calculate the centroid for both clusters each and then common centroid

How to find the ideal no. of clusters?

look into the graph, and take a longest verticle line where it does not get cut by any horizontal line, divide from there

Benefits :
1. widely used, can work good on complex patterns
2. we have the info that particular point is closest to which point because of dendogram
Limitations :
1. we are measuring distance between each points, at almost every step, so the matrix calculation will take a lot of space and computations, so not good for large dataset
KNN :

How to select k?
1.

Generally, this technique is not advicable
2. experiment for k = [1,...25]
so, 25 models, and select the model with highest accuracy
Decision Surface :

take the range for x and y, for each pixel in the grid, send each pixel/point it to knn model, and if it is 0, mark blue, if 1 , mark orange
for very small k value, chances of overfitting is there

underfitting for very high k value, lets say total 100 points, 70 orange, 30 blue, but if k is >95 or something, then, if you take majority, it will always be orange
limitaitions of KNN :
1. if very large dataset, it will take a lot of time during prediction

2. high dimension data : f=500, it is said that for high dim data, distance is not good metric, there is a chance of error and knn totally relies on distance
3. outliers

4.

5. we don't know which feature has how much weight for the output, it works like black box model
Assumptions of Linear Regression

1. each feature is expected to have linear relationship with output

2. There should not be multi-colinearity, features should not depend on each other. In below graph, values are too small, so they don't depend on each other

3. Error should be normally ditributed.



4. it must have homoscedasticity, it is also related to residual

5. there should not be any pattern in residuals

1st is not valid, 2nd is correct
SVM


SVM kernels for classifying this type of data :




how does it work?
it just converts 2d data to 3d data in a way that middle points are higher than side points by using some mathematical function

A. Adaboost vs B.Gradient Boost
- A - max depth of decision tree=1
- B - max leaf node - (8 to 32)
Probabilities :
Independent events:
event that does not depend on outcome of prev events
let's say, you flipped a coin 3 times, and got a Head
now, for the 4th time, probability of Head is gonna remain same 1/2, it is independent of previous results



Proof of equation :



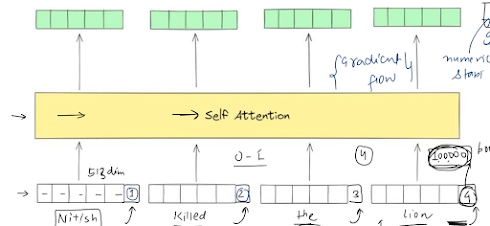
XG Boost



parallel processing : Example : we can calculate gini index for each feature parallely
Performance

1 = better regularization, less chance for overfitting because of added regularization term in equation


XGBoost for Regression
Initial setup is same as gradient boosting

step 1 : mean

step 5 : calculate similarity score fro left and right node, and then gain, whichever splitting criteria gives highest gain is needed to us.

step 6 : 8.25 was giving max gain, so





XGBoost for Classification






DBSCAN Clustering
















5.2 - custom loss function

baysian

Optuna library/framework
ROC Curve






Comments
Post a Comment