In this blog, we'll explore a complete Python solution that detects and extracts tables and text from images using libraries like Transformers, OpenCV, PaddleOCR, and easyOCR. This step-by-step breakdown includes code to detect tables, extract content from individual table cells, and retrieve any remaining text in the image. Overview When working with scanned documents, such as invoices or forms, it is essential to accurately extract both structured information (like tables) and unstructured text. The approach we’ll explore uses Microsoft's pretrained object detection model to locate tables and OCR techniques to extract the text from both table cells and the rest of the image. Steps: 1. This code first detects table using microsoft's model. and save that image which contains detected table only 2. After that, from the detected table , we make a seperate image for each cell. 3. Then we read text from the image of each cell 4. Now, to read the extra texts except for the ...
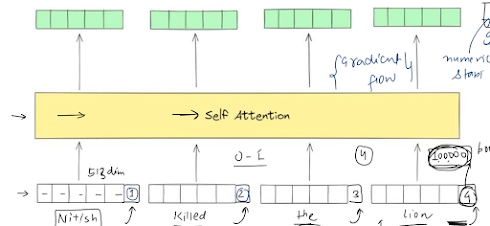
1. Why Position Matters in Transformers? Transformers rely on self‑attention, which processes tokens in parallel. This means, unlike RNNs, they don’t inherently know the order of words. So, sentences like “Ravi killed the lion” vs. “The lion killed Ravi” would look identical to a vanilla Transformer—clearly problematic! 🧪 Idea #1: The Naïve Approach A simple fix would be to add index/position of the token in an embedding vector. Issues: Unbounded values: Position IDs can become huge (e.g. 100,000+ in long texts), destabilizing training. Discrete steps: Sharp jumps between integers disrupt gradient flow. 🧪 Idea #2: Normalize the Position Numbers What if we divide the position numbers by a constant to make them small and smooth? That helps a bit—values don’t explode anymore. Issues: Now, if you observe, in both the sentences, the word at second position has got the different values. 1 for sentence1, and 0.5 for sentence2. so, the Neural network will get confused while training, what a...
Now, two question arises. Q1 : How do we know that we have get Purity / Pure split? There are 2 methods to find it out : 1) Entropy (Good) 2) Gini Impurity (Better because it's faster) Q2 : How does the features are selected? Information Gain 1) Entropy : H ( S ) = − ∑ i = 1 c p i lo g 2 ( p i ) Where: 𝑐 c is the number of classes in the output. Example : As you can see in the above diagram, for the component 'Overcast', we have 4 yes, 0 No. Total =4 Now, let's calculate Entropy for this Component. H ( S ) = − p yes lo g 2 ( p yes ) − p no lo g 2 ( p no ) H ( S ) = − 4 4 lo g 2 ( 4 4 ) − 4 0 lo g 2 ( 4 0 ) = -1(0) - 0 ...












Comments
Post a Comment