Image and Video Generation Developer Guide
Image Generation Prompting
subject = "a simple slide"
action = "explaining visual proof of the Pythagorean theorem"
location = "white background"
camera_control = "eye-level shot"
lighting = "white light"
style = "minimalist"
keywords = [subject, action, location, camera_control, lighting, style]
action = "explaining visual proof of the Pythagorean theorem"
location = "white background"
camera_control = "eye-level shot"
lighting = "white light"
style = "minimalist"
keywords = [subject, action, location, camera_control, lighting, style]
gemini_prompt = f"""
Your task is to expand the following keywords into a single, high-fidelity,
descriptive prompt for image generation. Every single keyword MUST be
included. Include reference images if provided and use that image as a
reference style guide for generated images. Output ONLY the final prompt
string, without any introduction or explanation. Mandatory Keywords:
{",".join(keywords)}
"""
Image Evaluation Techniques
1. SigLIP
- Gives us a match score between the prompt embedding and the generated image embedding.
- Limitation: We do not know the underlying reason behind a low score.

2. LLM Call

3. Gecko
- It breaks down the prompt and verifies if each minor detail is present.
- Example: "A white cat sitting on a pink chair"
- Is the cat white?
- Is there a chair?
- Is the chair pink?



Evaluation Summary
| Method & Scores | What it Tells You | What it Misses |
|---|---|---|
| SigLIP Aligned: 0.9999 Misaligned: 0.0000 |
Overall alignment as a single numerical score. | Cannot explain the reason behind the score. |
| Gemini Aligned: 4.8/5 Misaligned: 2/5 |
Multi-dimensional assessment paired with written explanations. | Cannot pinpoint highly specific element failures. |
| Gecko Per-element pass/fail |
Exactly which individual prompt elements passed or failed. | Less flexible when handling subjective criteria. |
Recommendation Strategy: Use SigLIP for speed → Gemini/Gecko for depth
Image Generation Agent Workflow
For creating contextually relevant designs matching your website's core theme:
Step 1: [Tool:
get_design_themes]Input: Your current website image. The LLM extracts and provides the key design themes of your platform using the following prompt structure:
prompt = f"""
Based on the following user description and brand guidelines, generate a
single comprehensive UI design concept for a web application.
User Description: {user_description}
Brand Guidelines (extracted keywords): {brand_guidelines}
For the concept, provide:
* Title: A concise and evocative name for the design concept.
* Design Description: A detailed description of the layout, color
palette, typography, and key visual elements, explaining how it aligns
with the user's description and brand identity.
* Nano Banana Prompt: A specific text prompt that can be used with
Nano Banana to create a photorealistic or illustrative mockup UI
rendering of this concept. Focus on visual details.
Ensure the concept fulfills all of the user's core requirements and maintains brand consistency.
"""
Step 2: [Tool:
generate_prompt_accordingTo_designTheme]Based on the extracted design themes and added user requirements, construct a precise text prompt to generate a cohesive new image.
Step 3: [Tool:
generate_image]Pass the structured prompt generated in Step 2 into the image generation model to render the final asset.
Step 4: [Tool:
evaluate_image]Evaluate the final image. Provide the LLM with the original image, the generated image from Step 3, and the target design themes to verify aesthetic alignment.
Step 5: [Agent Orchestration]
Provide the overarching project requirements and tool execution access directly to the Agent framework.

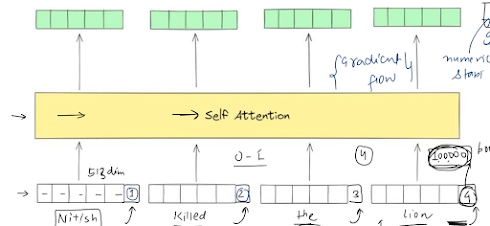
Video Generation Prompt Engineering

Long Video Generation Pipeline
- Step 1: User Prompt — Capture the core creative objective from the user.
- Step 2 [Tool]: LLM Scene Parsing — Execute an LLM call to break down the query into distinct video scenes. This outputs a structural JSON file containing 3 key parameters per scene:
- •
"narration": The spoken audio script content. - •
"camera_motion": Explicit physical or dynamic directional paths. - •
"image_prompt": Detailed context framework for the visual layer.
- •
- Step 3 [Tool]: Image Composition — Iterate through the structured JSON fields to trigger an LLM-driven generation step for every designated scene's background image layer.
- Step 4 [Tool]: Video Synthesis — Map the respective structural narrative script elements along with defined auditory characteristics (e.g., calm voice, pitch profiles, rhythmic flow, speech speed metrics) and the compiled visual canvas from Step 3. Process this collection inside the generator to output an initial 8-second video sequence.
- Step 5 [Tool]: Output Evaluation — Route the combined prompt context and output sequence through an verification LLM. Validate compliance constraints across both visual assets and audio arrays:
- If an asset contains a visual defect, re-trigger the image generation tool and pass the new canvas into the video compilation stack.
- If an asset contains an auditory defect, preserve the correct image canvas and exclusively rebuild the sound parameters using the video synthesis tool.
- Step 6 [Agent Control Layer]: Inform the unified Agent framework of the exact end-user goals, dictating precise condition maps defining exactly when to leverage specific tools along the processing pipeline.


Comments
Post a Comment